


-
22 February 2022
- Airflow
The new version of Airflow enables users to manage workflow more efficiently. We’ve described some changes in detail in our articles, and we can assure you about its improved performance. Apache Airflow’s capability to run parallel tasks, ensured by using Kubernetes and CeleryExecutor, allows you to save a lot of time. You can use it to execute even 1000 parallel tasks in only 5 minutes. Are you intrigued yet?
Introduction
Airflow is a popular piece of workflow management software for program development, task planning and workflow monitoring. It has its own capabilities and limitations. Can you run 1000 parallel tasks in Airflow? As you might guess — yes! In this case, Celery Executor comes to the rescue. Airflow offers many executors, but for multiple tasks it is good to use Celery Executor. In this exercise, we used parts of our latest product, based on Airflow 2.0 service, which is being actively developed by DS Stream (therefore we cannot provide the full code to recreate the job). If you are interested in details, please contact sales. Soon, more details about this project will also be available on our website.
Celery Executor
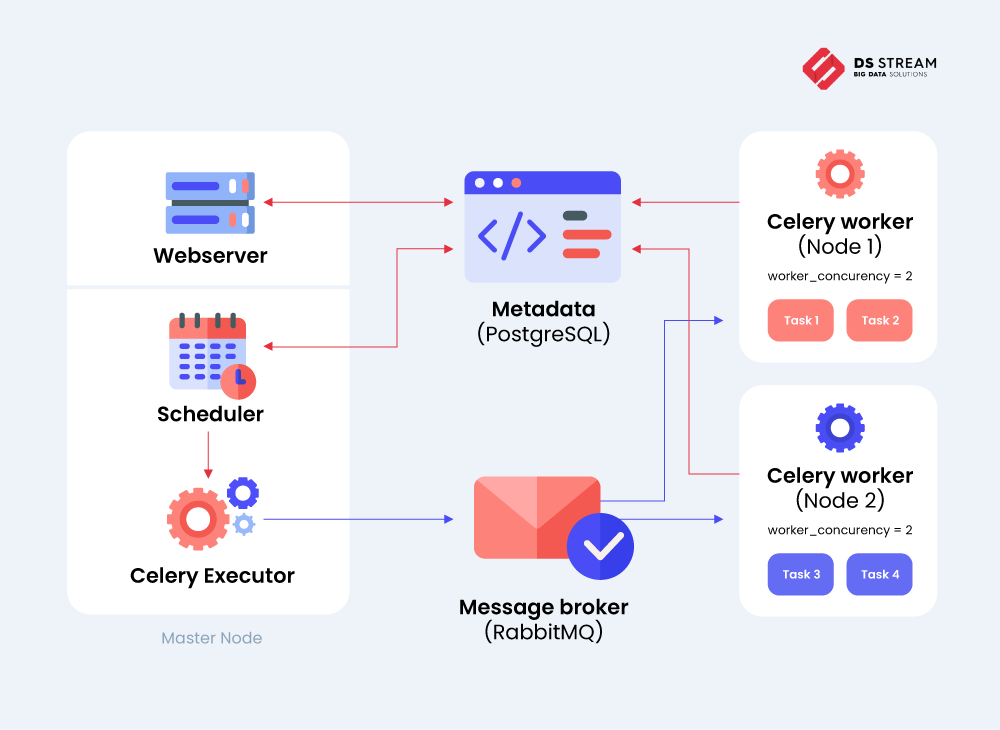
Let’s start with explaining what an executor is in the Airflow system. This is a mechanism by which scheduled tasks are carried out. The worker is a processor or a node which runs the actual task. When talking about Apache Airflow parallel tasks, we have to remember that Airflow itself does not run any tasks. It just passes them on to the executor, which is then responsible for running this task with the best use of available resources.
Celery is an asynchronous task queue. It’s able to distribute scheduled tasks to multiple celery workers. So when we are using Celery Executor in Airflow setup, the workload is distributed among many celery workers using a message broker (e.g. RabbitMQ or Redis). The executor publishes a request to execute the task in a queue, and one of several workers receives the request and does it.
RabbitMQ is an open source message broker program. It ensures proper division of work between workers and successful communication between executor and workers.
The last step in properly configuring Celery Executor is to use an external database like PostgreSQL. This allows for task scheduling and real-time processing. The database is a remote contractor and can be used for horizontal scaling where workers are spread across multiple machines in a pipeline.
Configuring Airflow – parallel tasks
We will run our system on Kubernetes Service in Microsoft Azure. To do this, configure the Docker Image that will be used in the Airflow setup. When creating it, we are using the apache / airlfow image in version 2.1.4, available at https://hub.docker.com. Dockerfile’s code is below:
# Dockerfile code # Latest LTS version FROM apache/airflow:2.1.4 ENV AIRFLOW_HOME /opt/airflow RUN pip install --upgrade pip COPY --chown=airflow:root ./app/ ${AIRFLOW_HOME}
In the app/folder there is a dags/ folder containing all DAGs and the airflow.cfg file, which is used to configure the Airflow setup. The airflow.cfg template file is available on the Airflow github. These are the most important parameters that must be set in order to be able to run 1000 parallel tasks with Celery Executor:
- executor = CeleryExecutor
- worker_concurrency = 36 <- this variable states how many tasks can be run in parallel on one worker (in this case 28 workers will be used, so we need 36 parallel tasks – 28 * 36 = 1008)
- parallelism = 1000 <- enables running 1000 tasks in parallel
- max_active_tasks_per_dag = 1000 <- enables running 1000 tasks in parallel for one DAG
- max_queued_runs_per_dag = 1000 <- allows for parallel queuing of 1000 tasks in a DAG
Next, we need to create 4 more yaml files, which will create the necessary deployments, services and configMaps in Kubernetes:
- namespace.yaml
- postgres.yaml
- airflow.yaml
- celery.yaml
In the next step, you need to prepare the Kubernetes environment in Azure (create a cluster and build an image based on the previously prepared Dockerfile).
# Create resource group az acr create --resource-group ${RESOURCE_GROUP} --name ${ACR_NAME} --sku Basic # Create Kubernetes service az aks create \ --resource-group ${RESOURCE_GROUP} \ --name ${CLUSTER_NAME} \ --node-count 6\ --nodepool-name nodepool1 \ --attach-acr ${ACR_NAME} --generate-ssh-keys \ --kubernetes-version 1.20.9 \ --node-vm-size Standard_E4s_v3 # Build image based on Dockerfile az acr build --registry $ACR_NAME --image airflow-worker:2.1.4 .
After this step, all you have to do is create all deployments on the cluster using kubectl and the prepared yaml files:
kubectl apply -f deployments/namespace.yaml kubectl apply -f deployments/postgres.yaml kubectl apply -f deployments/airflow.yaml kubectl apply -f https://github.com/rabbitmq/cluster-operator/releases/download/v1.10.0/cluster-operator.yml kubectl apply -f deployments/celery.yaml
Boom! After a few minutes, we have the Airflow setup configured, which will allow 1000 tasks to run simultaneously! We should get confirmation of this fact after running the command “kubectl –namespace=airflow get all”:

The DAG created for this example is designed to sleep for 100 seconds:
import time from datetime import datetime from airflow.models import DAG from airflow.operators.python_operator import PythonOperator def test(**context): time.sleep(100) default_args = { "owner": 'Airflow', "start_date": datetime(2021, 1, 1), } dag = DAG( dag_id='test_1000_task_1', schedule_interval="0 * * * *", default_args=default_args, catchup=False ) with dag: for i in range(1000): task = PythonOperator( task_id=f"task_{i}", python_callable=test, provide_context=True )
Running Airflow parallel tasks — test configurations
Finally, all that remains is to check if the tasks start correctly. For this purpose, we run our sample DAG:




Conclusion
We are happy that we could give you some tips on Airflow’s configuration. You can benefit from running Apache Airflow parallel tasks smoothly, following our advice. We have just proved that it’s possible to create an Airflow setup in a short time which will allow you to run even 1000 parallel tasks! This is something! This means that Airflow can be used both for small, undemanding projects and much larger ones, reaching hundreds or even a thousand tasks. How can Airflow help your business? Visit our Data Pipeline Automation page and find a solution that suits your needs. The entire Airflow startup process will be automated by our application, which will allow you to set up the entire infrastructure with one click. In its construction, modern concepts and technologies, such as CI/CD, Terraform or Kubernetes, will be used. For more details — contact sales.
Learn more about Airflow 2.0:
- A more efficient scheduler to improve performance in Airflow 2.0
- Powerful REST API in Airflow 2.0 — what do you need to know?
- How to simplify Airflow 2.0 setup with the DAG Versioning and Serialization


