
Traditional data transformation tools are usually all-in-one monolithic platforms that lacks customization and flexibility. From few years trends are changing towards more specialized services like transformation, orchestration, testing, UI etc. Integrating separate tools can lead to deliver better data to customer and overall experience. Modern approach means that development process can be iterative and incremental, with full automation and continuous delivery.In this article we will use tools:
- dbt
- re_data
- Airflow
as an example, for building modern data transformation pipeline.
dbt
dbt is a transformation workflow framework for data models. Models are using SQL statements that describe transformations and are executed on target data platform: BigQuery, Databricks, Postgres, Snowflake and many more. Models can be combined from other models which leads to reusable framework with ready to use building blocks. This modular nature allows to break logic into simpler, smaller parts that can be reused in different transformations. Compared to traditional tools we don’t have to repeat complex logic in multiple pipelines – often copied from pipeline to pipeline.
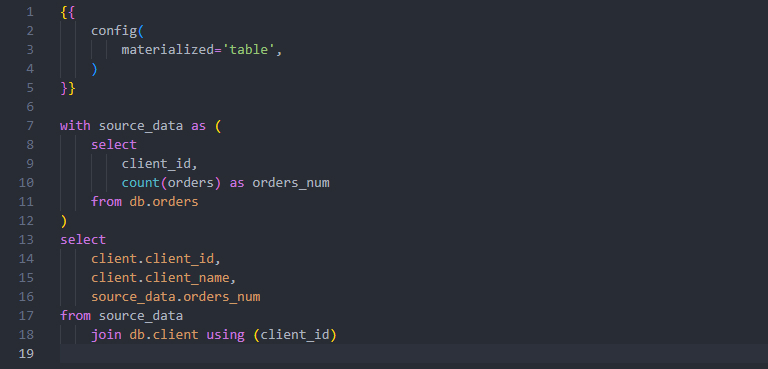
[Sample model: client.sql]The dbt code is stored in one place (on git repository) to provide single source of truth. We can group data models into packages, version them and add detailed documentation. Documentation can be written in plain text or markdown to describe project, sources, models columns and more. Rendered documentation is a simple website with sections and graphs for better project visibility and understanding.

[Sample documentation generated by dbt]Each model can have tests executed during development and runtime. Tests are SQL files that can check for example not null values, unique values or reference (if id values correspond with the same id value in other model). Tests in dbt works like unit tests in programming – they are confirming that code works correctly and allows to make controlled changes in the models.

[Test example: assert_client_total_amount.sql]dbt is available in 2 versions:
- dbt core - open-source, command line tool with all transformation functionalities.
- dbt cloud – essentially, it’s a dbt core but with cloud-based UI. UI has additional functionalities like metadata, automatic documentation rendering, integration with other tools.
In conclusion, working with dbt allow users to focus on business logic while creating data models and framework will handle execution order and object creation. Data models create trusted source for reporting, ML modeling or other pipelines. Modular approach with reusable data models makes it easier to start working on data analysis – we don’t have to build pipeline “from the ground”.
re_data
re_data is an open-source framework that is extending dbt with data quality-oriented tests and metrics. This solution enables to track data changes, monitor results, inspect data lineage, and project details. Any anomalies detected in data can be sent as notification on Slack or email.Time-based metrics are gathered for monitored tables and can be extended by user defined calculations. Already built-in metrics are set of standard calculations on table data like row count, min value, max value, null count, etc. Metrics can be later tested to detect problems - re_data delivers library with ready to use asserts. All tests’ results are stored and can be later analyzed to find problems with data.
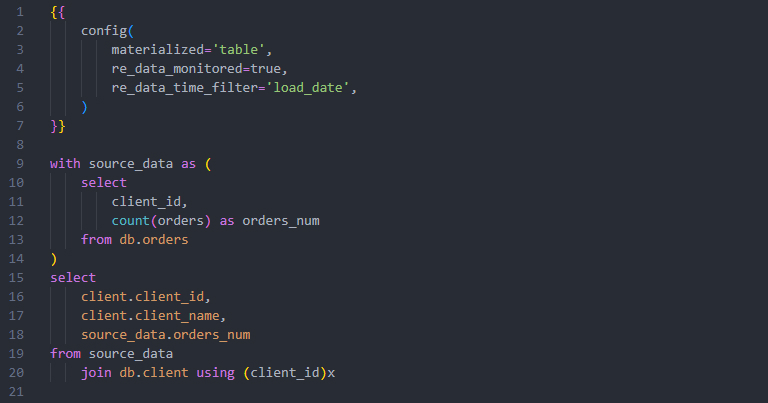
[Sample dbt model with re_data: client.sql]Version 2:
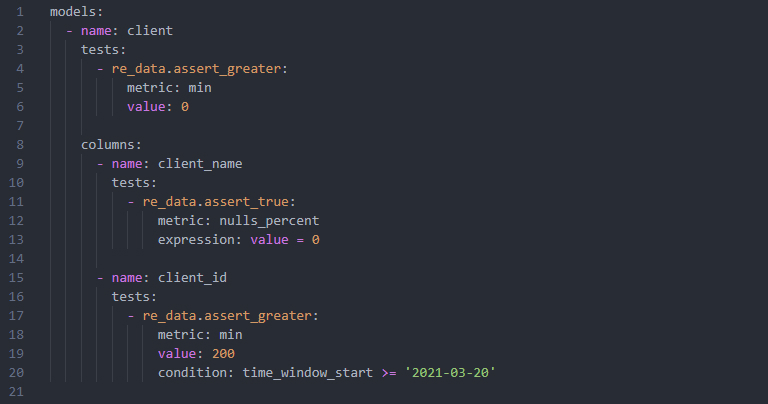
[dbt model configuration with re_data tests: schema.yml]With re_data we can also generate UI that have detailed information:
- alerts with any problems with the data or schema changes
- data lineage with additional information about anomalies
- tests history
- tables with details about metrics and tests associated with it

[UI example, image from re_data documentation: https://docs.getre.io/latest/docs/re_data/getting_started/toy_shop/generate_ui]More enterprise solution is re_cloud. It’s a cloud-based solution that can integrate all re_data outputs in one place. re_cloud can integrate with multiple solutions like: BigQuery, Redshift, Snowflake, dbt, GreatExpectations and more. It can be a single point of monitoring where users from different teams can check reports and alerts.
Airflow
Airflow is an orchestration tool written in python. Because it’s highly customizable (custom python code can be added as plugins) we can add any functionality that we need. With Airflow we can create processing workflows that are executing needed transformation steps at desired schedule.

[Example of Airflow DAG]
Summary
With a combination of dbt, re_data and Airflow we gain:
- Work is separated between specialized teams with more clarity who is responsible for what
- Data is reliable because of business and data quality checks implemented with constant monitoring and alerting
- Tools can be enhanced with other “blocks” if needed. For example, we can add GreatExpectations if we want to test input data.
- Development process is iterative and incremental, with proper version control.
Example architecture is on the picture below:

Stateful-vs-stateless architecture which solution is better for your application
Data exploration-definition and techniques
Everything you need to know about data quality management-best-practices-and-tools


.webp)
