


-
8 September 2021
- Big Data
Every program has a database. It’s where you store all the information necessary for your software to perform its operations. In this article, we’re going to explore one of the most common types of databases — a relational database.
Before we explain what “relational” means, let’s brush up on the basics: what is a database? It’s pretty simple. A database is a collection of data saved in an appropriate format. The format in which your data is saved determines how you can access that data.
Depending on the application, data is saved differently, and the way data is written has an impact on the performance of individual operations (writing, reading, deleting and modifying data). If you want to know more about data engineering visit our data engineering consultancy.
There are many types of databases, and the relational database is a very popular one.
What Is a Relational Database?
The term “relational database” was first introduced in 1970 by Dr. Edgar Ted Codd of IBM.
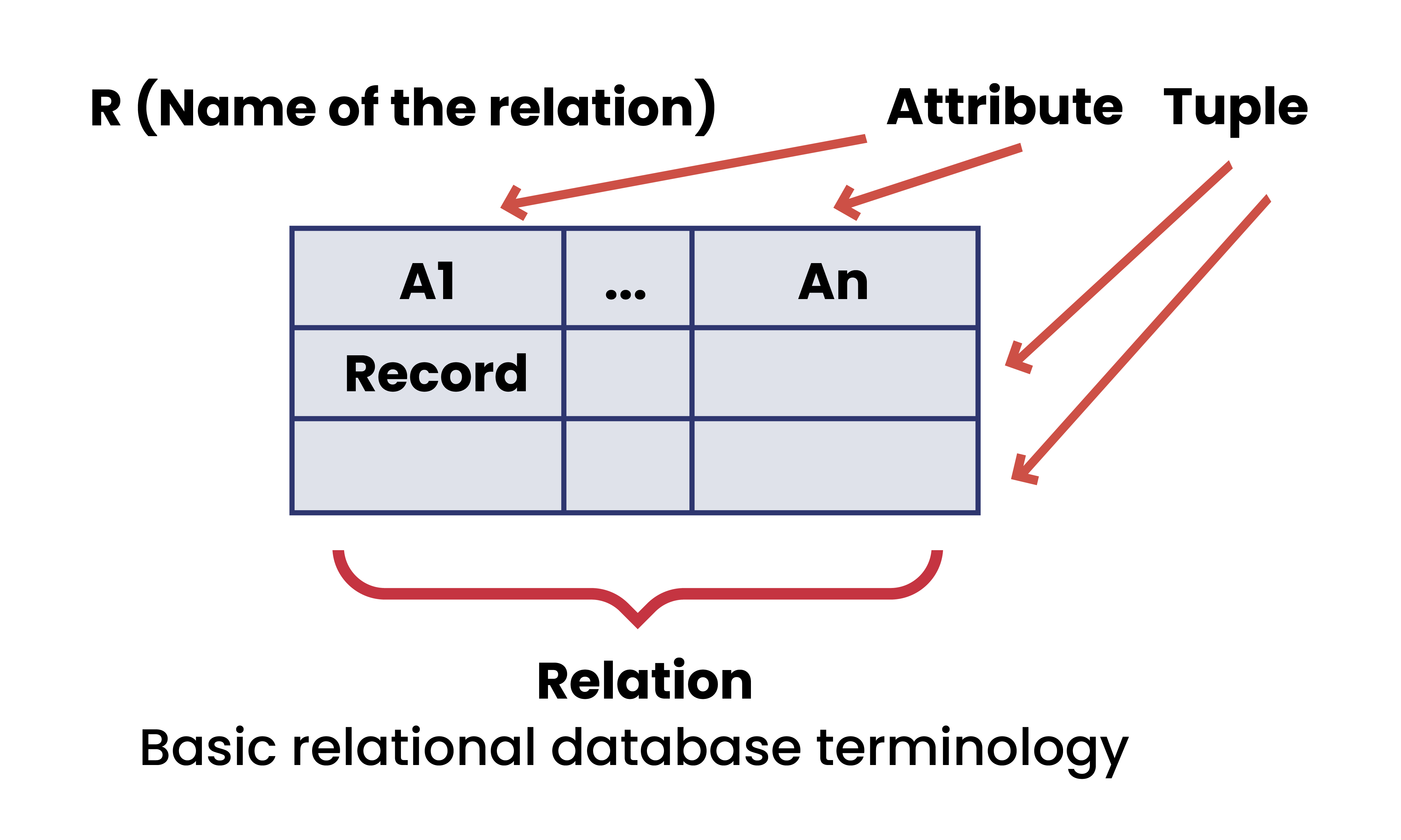
In a relational database, you (as the user) configure the relationships you want, and information is stored and retrieved according to your configuration. In this model, data is stored in simple linear files, which are called “relations” or “tables”.
Operations in relational databases are based on relational algebra. Relational algebra is a set of operators that manipulate relations; thus, the result and arguments of these operators are relations. These operators can be divided into two groups:
- Operations on sets
- Operators designed for the relational model
The relational model introduced SQL (Structured Query Language), which is the main language used to access and modify data in databases.
The Basics of Relational Database Implementation
Databases have different implementations. They also differ in the version of SQL they support. Although there’s a standard that describes the SQL language, there are some slight differences between the SQL supported by individual databases. The different versions of SQL are called dialects.
You can come across many relational database implementations. A few of the most used implementations are listed below:
- PostgreSQL
- MySQL
- SQLite
- Oracle
- SQL Server
- HyperSQL
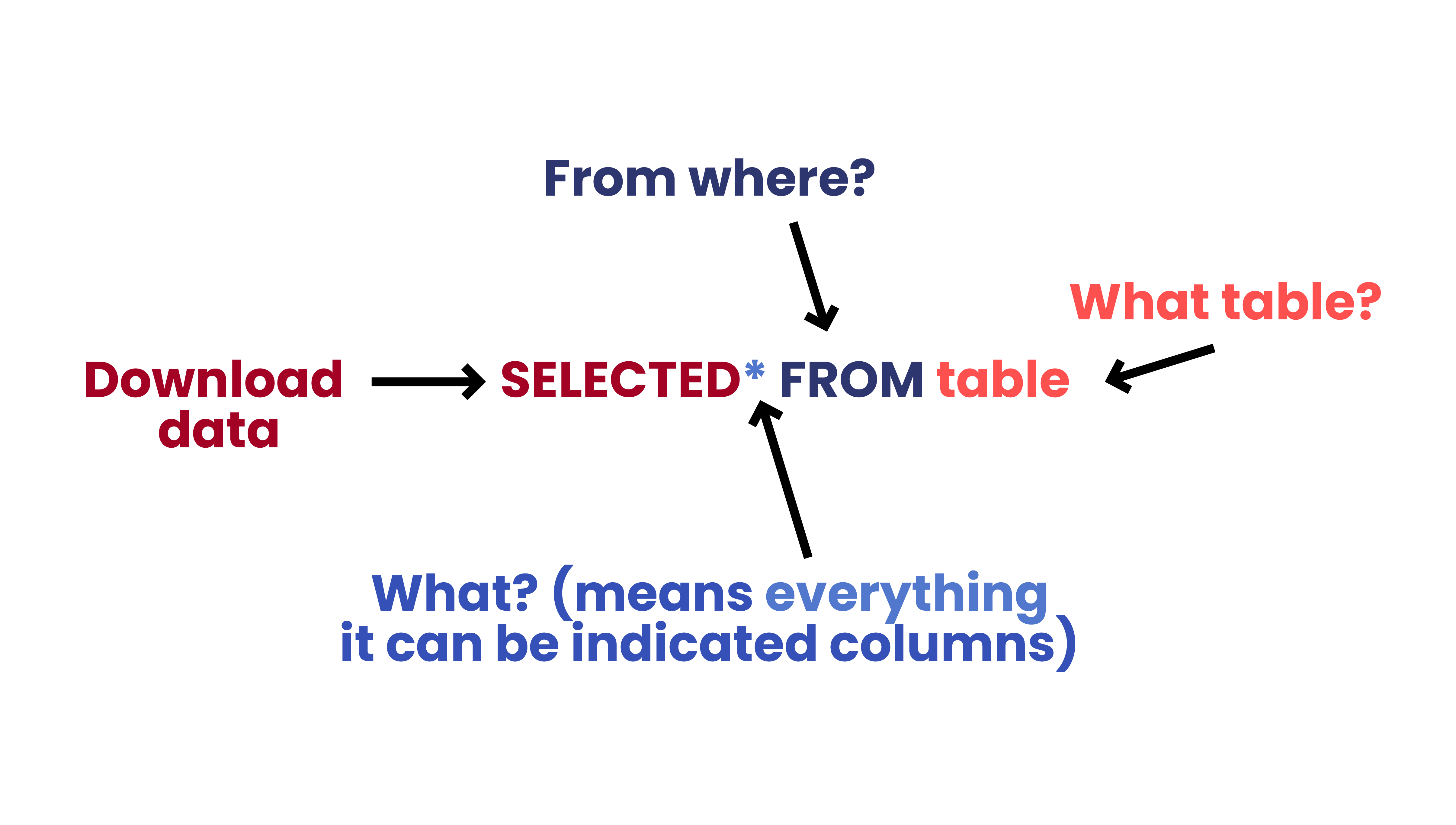
The basic operating unit of the SQL language is a query. There are three basic types of data search queries (these are what’s known as select queries):
- Projection (selection of only some fields/attributes, features, columns)
- Selection (selection of records/rows meeting one specified condition)
- Joining (merging data from different tables)
The query pattern is shown below:
Advantages of Relational Databases
There are three key things that make relational databases very useful:
- A simple but powerful relational model can be used by enterprises of all types and sizes to meet a wide range of information needs.
- Relational databases can be used to track inventory, process e-commerce transactions, manage large amounts of key customer information, and more.
- A relational database can be used to meet any information needs in situations where data items are interrelated and need to be managed in a secure, rule-based, and consistent manner.
Even though relational databases have existed since the 1970s, the advantages of the relational model have made it the most widely accepted database model until this day, and it’s probably going to stay that way in the foreseeable future.
What Do You Need To Consider When Choosing A Relational Database?
The software used to store, retrieve, manage and modify the data stored in a relational database is called a relational database management system (RDBMS).
An RDBMS provides an interface between users, applications, and the database. A database management system also gives you access to administrative functions for easier management of data storage, access, and performance.
There are several factors that influence the selection of a specific type of database and relational database products. The choice of RDBMS depends on the business needs of the company. If you’re making this choice, you should ask yourself the following questions:
- What are our data accuracy requirements?
- Does data retention and accuracy depend on business logic?
- Is our data subject to strict accuracy requirements (for example, financial data and reports to public authorities)?
- Do we need scalability?
- What is the scale of the managed data and what is the expected increase in its quantity? Will the database model need to support database mirroring (as separate instances) in order to scale? If so, can it maintain data consistency across these instances?
- How important is concurrency?
- Will multiple users and multiple applications need simultaneous data access? Does the database software support concurrency while protecting data?
- What are our performance and reliability needs? Do we need a product with high performance and reliability?
- What are the query response performance requirements? What are the vendor’s obligations regarding service level agreements (SLAs) or unplanned downtime?
The Main Rules of Relational Databases (And SQL)
Relational databases (as well as their standard, SQL) are based on four simple rules:
1. All data values are based on simple data types.
2. All data in the relational database is presented in the form of two-dimensional tables (called “relations“).
Each table contains zero or more rows (including “tuples”) and one or more columns (“attributes”). Each row is made up of equally arranged columns filled with values, which in turn can be different in each row.
3. After entering data into the database, it’s possible to compare values from different columns, usually also from different tables, and merge rows when their values match.
This enables data binding and relatively complex operations to be performed across the database. All operations are logical, regardless of the position of the table row. Rows in a relational database are stored in a completely arbitrary order – it doesn’t have to reflect the order in which they are entered or the order in which they are stored.
Types of relations:
- one-to-one (if a single record from the first table has at most one record from the second table, and vice versa)
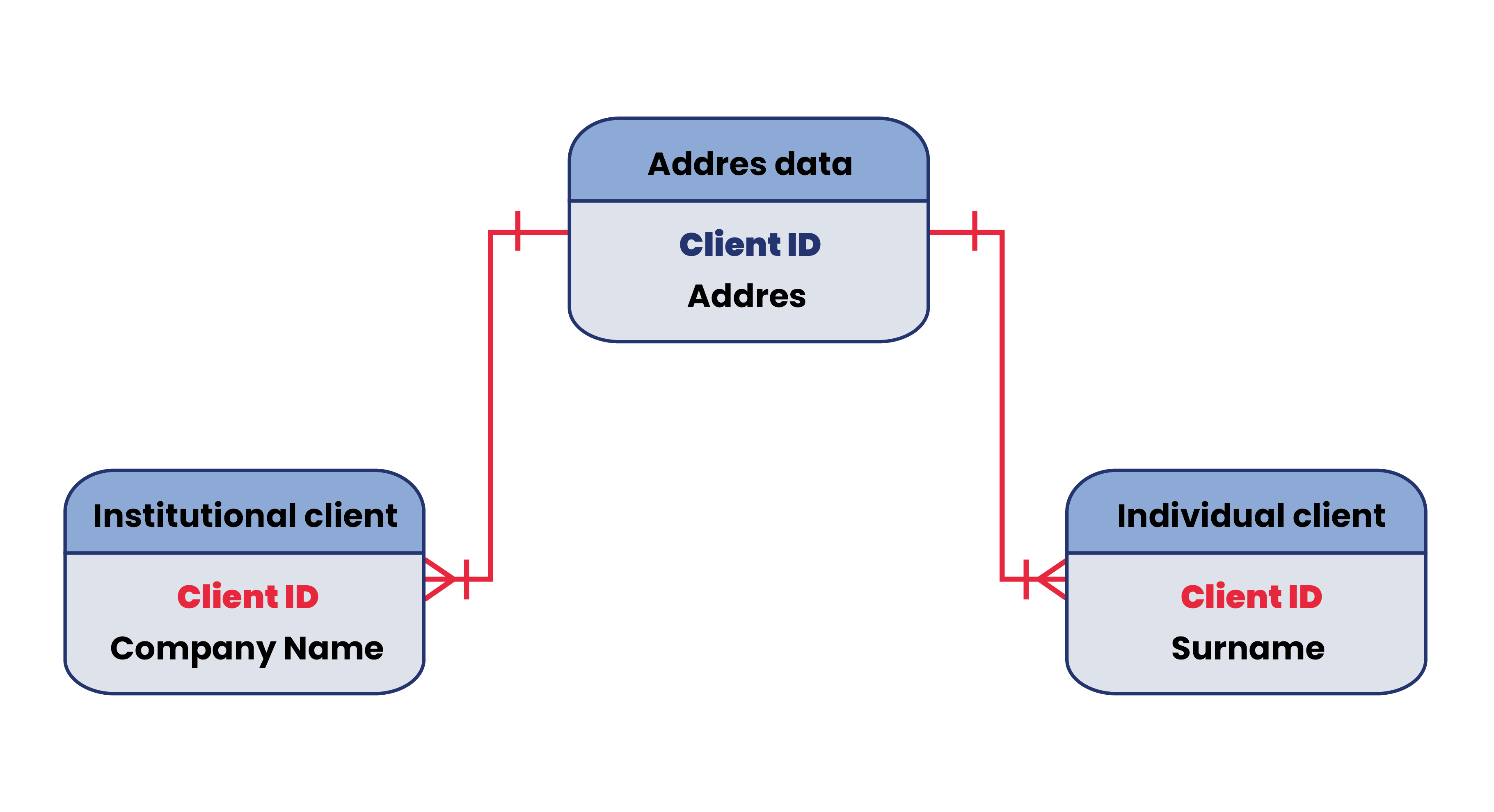
- one-to-many (if a single record from the first table can have one or more records from the second, but a single record from the second table has at most one record from the first table).
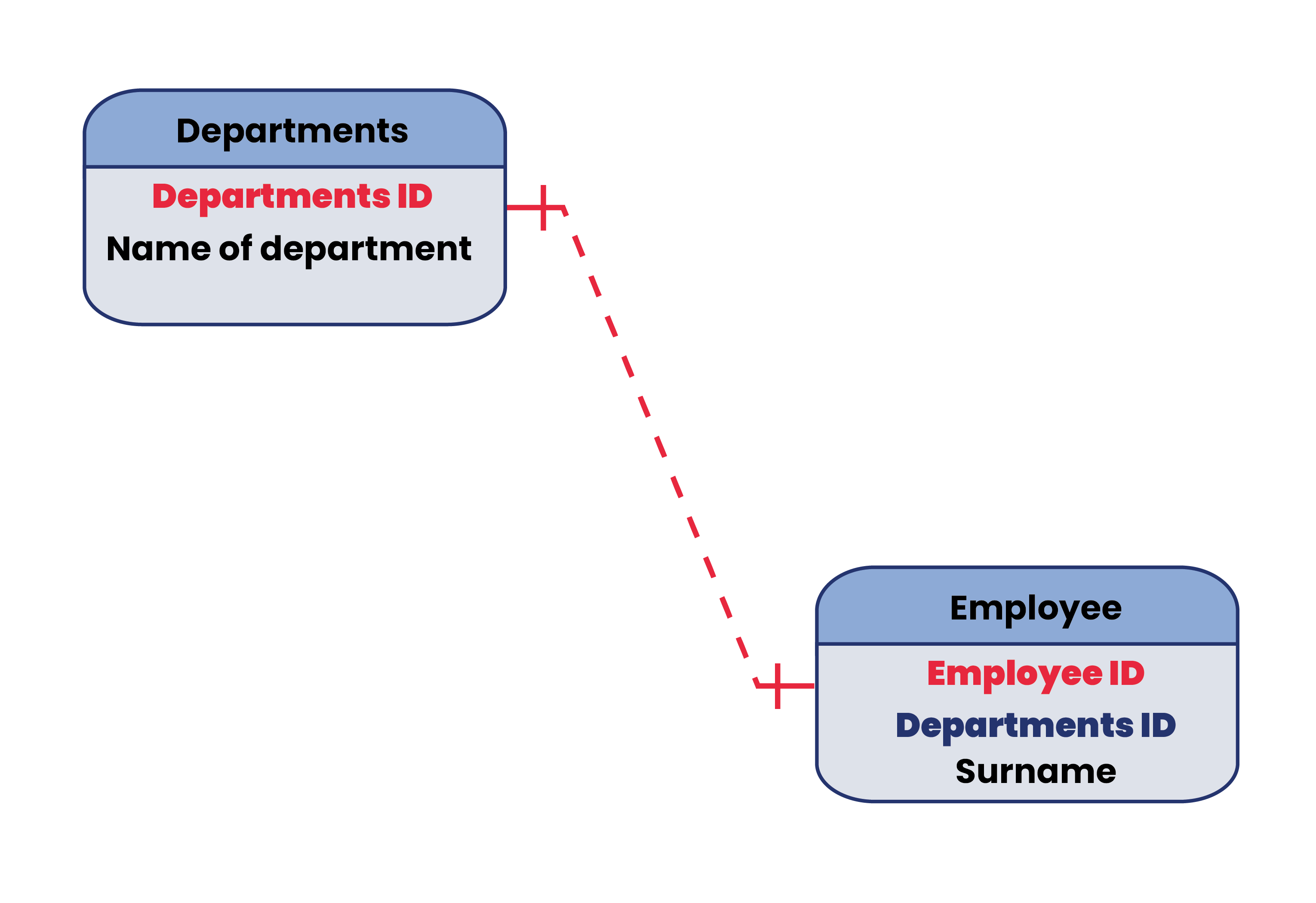
- many-to-many (occurs when one record from the first table has many records from the second table and one record from the second table has many records from the first table).
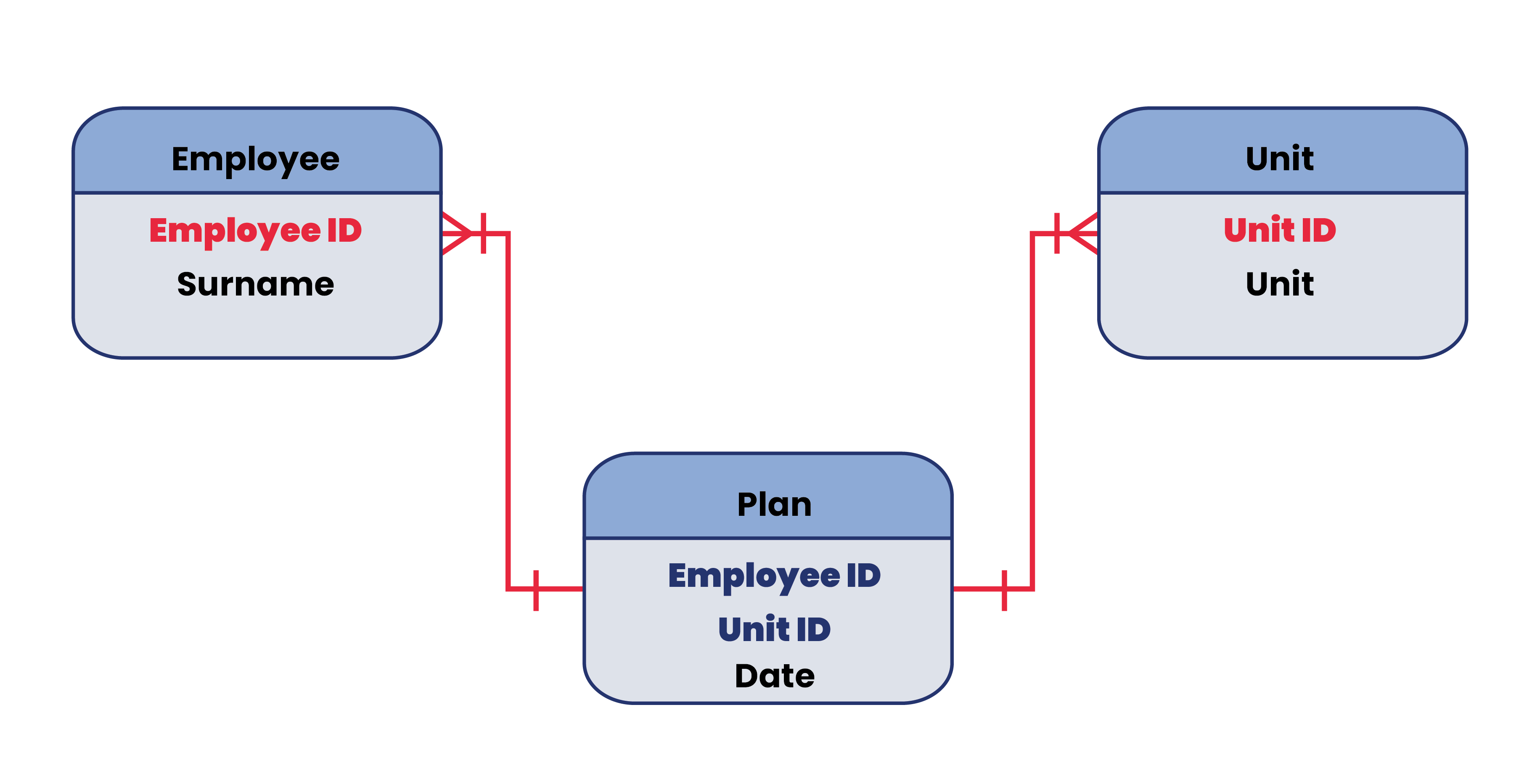
4. Since the row cannot be identified by its position, there need to be one or more unique columns within the entire table, making it possible to find a specific row.
These columns are known as the “primary key” of the table.
Note that the primary key isn’t always present in all tables. Plus, you can also have foreign keys — a bit like a hyperlink, a foreign key refers to the primary key from a different table, linking the two tables together.
To prepare the database, you follow this series of steps:
- Definition of requirements
- Pre-designing forms and reports
- Preparation of tables
- Defining the relations
- Creating forms
- Creating statements – queries and reports
To prepare tables, you follow these five rules:
- Assign one category of information to one table.
- There should be a single piece of information in each column of the table.
- Use names that will avoid confusion or ambiguity.
- Avoid repeating the same information in several tables.
- A list of data should not be stored in one field.
There are different inherent constraints in relational databases, such as the referential integrity constraint. For example, if you have two tables with a Customer ID row, ID #1 has to exist and be the same in both tables.
5. Data should be normalized
Normalization is about organizing data in such a way that it flows smoothly in, out, and around the database.
It’s a bit like organizing your suitcase for a long vacation. If you just throw everything in there randomly, you’ll have limited space and you’ll waste time digging through all of your belongings in order to find what you need.
But if you organize your suitcase with a few simple rules (for example, fold everything tightly, separate different groups of clothes, etc.), you suddenly have more space and everything is instantly accessible.
In relational databases, these rules are called “normal forms”. They don’t fit all real-world scenarios, but they’re a good benchmark to follow in order to make sure your database is consistent.
Disadvantages of relational databases
Not everyone’s a fan of relational databases. Software developers might not like this type of database, because:
It’s an old technology
The relational model was invented a year after the moon landing. Some programmers think it’s dated, and prefer to use modern alternatives.
The relational model and SQL language can be tricky
A programmer might not like the relational model or the SQL language. It’s a matter of preferences and project requirements, similar to choosing between Object-Oriented Programming or Functional Programming, or between Python and Ruby. A popular complaint with SQL and relational databases is that it’s difficult to make them do exactly what you want to.
Relational databases don’t scale well
It can become very expensive and difficult to maintain a relational database in a huge project (meaning something like Facebook, or an enterprise big data application). Some modern types of software simply wouldn’t work well with a relational database, which is why many alternatives have been created as a replacement.
There’s a lot of overhead
The relational model is built around a specific structure. It ensures the integrity of your data, but to do so, it forces you to jump over some hoops for simple operations like reading data. If you need a lot of flexibility when it comes to your data (especially if you have inconsistently structured data), you might need to look for an alternative.
When to use relational databases
Here are some basic guidelines when to use relational databases:
- When you have medium-level workloads, like thousands of operations per second (if you’re doing millions of transactions per second, SQL will slow you down).
- Your data is structured and doesn’t change all the time.
- Data relationships are based on normalized data models (if you need de-normalized data models, SQL won’t fit).
- You need to perform complex queries in your database (if you need simple queries only, SQL will be too much).
- You use proprietary hardware to deploy the database (if you’re using cloud hosting, it SQL might not be the best choice due to costs).
Alternatives to Relational Databases – Modern Database Models
Since relational databases are based on SQL, the alternatives are generally called NoSQL. There are different approaches to NoSQL, some of these databases even support query languages similar to SQL. The main differentiator of NoSQL is that these databases are non-relational.
There are four types of NoSQL databases:
- Key-value stores
This type of database is a lot like a dictionary (people actually call them dictionaries, as well as ‘hash tables’). A key is assigned to one, and only one, value in the database, and this is the foundation on which all relationships are built. It’s a simple type of database that scales very well, but it has limited functionality.
- Graph stores
Here, you don’t have tables. You have nodes and connections between them, where both nodes and connections can also have properties in the form of key-value pairs. The relational database is great if you need to define one relationship. When you have multiple nodes that are interconnected in complex ways, a relational database can’t handle it, and a graph store is much better.
- Column stores
This is like a relational database, only it stores data tables by column, and not by row. Because of this, a column store is great for applications for analytics. They’re good for calculating statistics on a large chunk of individual tables.
- Document stores
This is basically what the name says – a database that stores data in the form of documents (in the XML, JSON, or even PDF format). If your application doesn’t need tabular data, or you need fast in-memory access, a document store might be for you. Each document has its own schema (as opposed to a relational database, where every row in a table has to have the same columns).
Summary
Although the relational model is already a mature, 50-year-old technology, there’s still no alternative to replace it in the near future. The database market is developing all the time, and hence, the demand for database specialists is growing.
Modern organizations use databases not only to store data and execute transactions but also to analyze data. With databases and other processing and business intelligence tools, organizations can use the collected data to operate more efficiently, make better decisions, and improve flexibility and scalability.
When you’re creating a database for your project, choosing the right data model is a critical long-term decision. If you’re looking for support, we can help you make the right choice to ensure proper performance of your application at a reasonable cost.
Check out our blog for more details on Data Engineering:
