
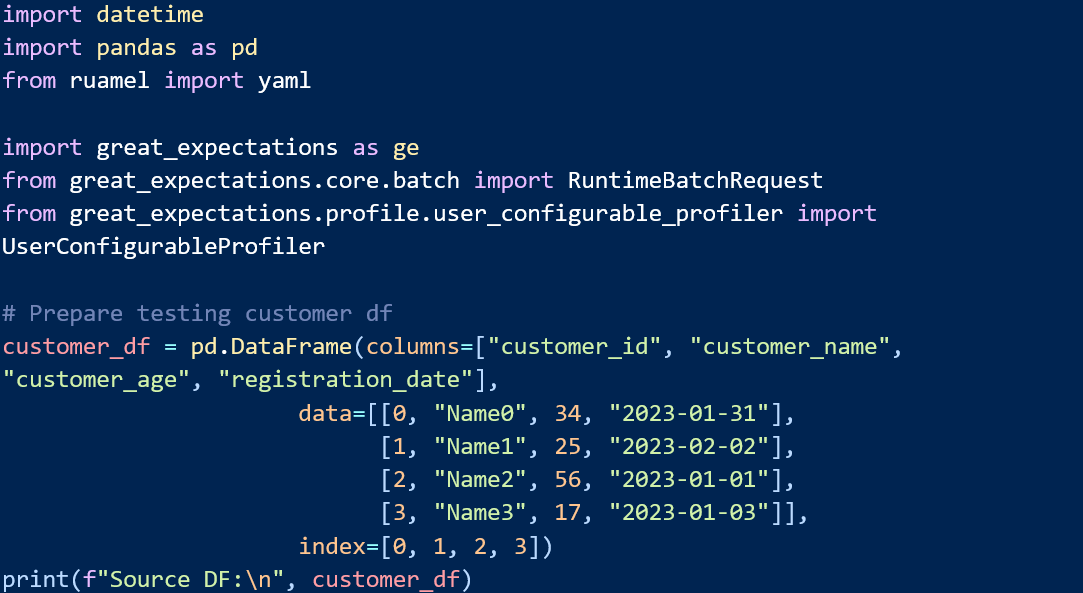
In today's data-driven world, the amount of data being produced and consumed is growing rapidly. However, many businesses struggle to fully utilize their data due to issues with data quality. That's where the Great Expectations (GX) framework comes in. It is a tool that helps businesses analyze their data and monitor its quality, allowing them to make better decisions based on reliable information. However, this is not only for data analysis, it can help you also in data management as it can be used to enforce, track and document the data quality rules. The GX can be as well extremely useful in data science, where you to provide good quality of data to an optimizer or a model. In this article, we will explore the GX framework and how it can be used to verify the quality of data. We will also provide a step-by-step guide on how to use the framework, including installation, integration with various databases, and data verification.
How to start with GX?
The only step to start playing GX is to install it using the following command: pip install great_expectations and great_expectations init after that. You can setup default values of your environment before the real work with GX, however for the case of this scenario the setup will be done in code, before data validation.GX supports connection to multiple databases like BigQuery, MySQL, PostgreSQL, Redshift, Snowflake etc. Data stored in files can be automatically loaded to Pandas & Spark DFs, even in memory data can be tested right away. In this article we will cover Pandas DF in-memory data verification.
Next step is to define your data source and save it to GX context. It can also be done in GX configuration and used later on without providing it.

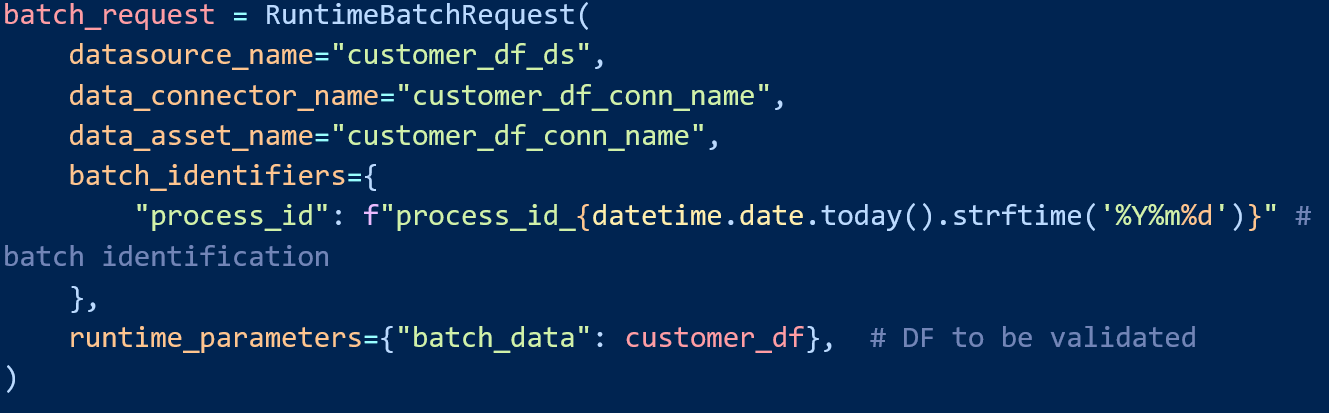
Afterwards we need to create Batch Request object defining data to be tested.
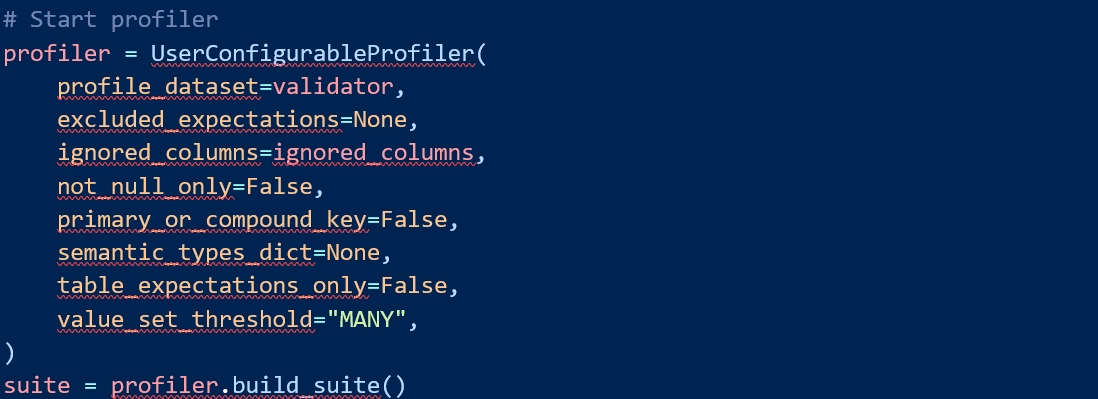
Now is the time to create empty expectation suite (set of tests) and play using built-in expectations:

Below are presented the results of tests, worth to mention that GX will raise an error if the column does not exist in data. We should test it first using table level expectation like expect_table_columns_to_match_set.

You can permanently save tests into expectation suite which later on can be easily loaded and used in checkpoints using the below command.

Failed expectations can be skipped by changing the discard_failed_expectations parameter to True.
Analyze your data using profiler
GX profiler can help you to create set of expectations for your new data set. Once the validator is set up, the rest is rather simple. Profiler has a lot of options to control, for the case of this scenario only the “customer_name” column is excluded from the analysis.

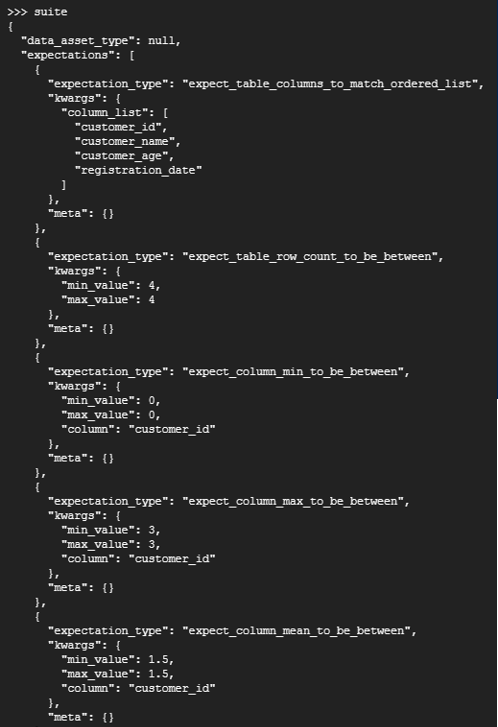
The following screen presents just part of tests profiler has proposed to us. Worth to mention that some of them will make no sense for us, so they can be dropped later on. Expectations are saved as JSON files, so there is a possibility to go through the file with tests and delete/modify the expectations there.
Checkpoints
The previous solutions are good for developing & testing purposes, and not production environment. With the help of the latter comes the checkpoint. It groups multiple actions including running tests, generating documentation/validation reports, uploading them to cloud storage if needed and notifying about the errors through multiple channels like email or slack. The example code to configure & run the checkpoint is presented below

During checkpoints development the results can be verified from printed JSON data, however there is much easier way of doing it. In the main great expectation directory, you can find multiple directories including great_expectations/uncommitted/data_docs/local_site in which the documentation of expectation suites & validations can be found. The checkpoint we specified above has generated the following report.

Pros & cons
Great Expectations is a big open-source framework with lots of functionalities. The tool can be extremely useful to verify the quality of your data, however you need be aware of its limitations.Pros:
- Support multiple data sources: spark, pandas, BigQuery, Athena, PostgreSQL, MySQL and more
- Native tool for python developer
- Tests can be performed based on saved set of expectations as well as dynamically through validator
- Integrated with dbt framework
- Available validation notifications on slack/email etc.
- Integrations with clouds disks
- Possibility to extend built-in expectations
- Expectations can be modified directly in JSONs or created through python code
- HTML documentation of tests & validation reports
Cons:
- Maintaining similar set of tests can be painful, all of them needs to be changed separately.
- Big list of dependencies may cause conflicts in your project
- The framework is constantly improved, however, there may be errors that are difficult to diagnose and which will not be fixed quickly
Summary
The article introduces the Great Expectations (GX) framework, which can help businesses analyze and monitor the quality of their data. The framework easily integrates with the dbt transformation engine and supports connection to multiple databases. The article provides a step-by-step guide to using GX, including setting up a data source, creating a Batch Request object, and defining tests using built-in expectations. The article also discusses the GX profiler, which can help create a set of expectations for a new dataset, and checkpoints for production environments. Overall, the article provides a comprehensive overview of how to use GX for data validation and monitoring.
Data science in action the role of machine learning in predictive analytics
Test driven development in python using pytest
What is the data conversion process and why should you execute it


.webp)
