In den frühen Tagen von Big Data war der Weg klar: Sie schrieben ein Skript, hängten es an einen Cron-Job und hofften auf das Beste. Wenn Sie komplexe Abhängigkeiten benötigten, orchestrierten Sie diese möglicherweise extern mit Oozie, Airflow oder Azure Data Factory.
Heute hat sich die Landschaft verändert. Mit der Reife von Databricks Workflows und dem Aufstieg von Delta Live Tables (DLT) stehen Data Engineers vor einer grundlegenden Wahl in Bezug auf Architekturparadigmen: Imperativ vs. Deklarativ.
Wenn wir skalierbare Pipelines mit Azure und Databricks aufbauen, lautet die Frage nicht nur "Was funktioniert?", sondern "Was passt zur Engineering-Kultur, zum Wartungszyklus und zum Budget des Projekts?"
In diesem Artikel werden wir die theoretischen Grundlagen untersuchen, die betrieblichen Unterschiede beleuchten und einen klaren Entscheidungsrahmen für die Implementierung Ihrer nächsten Datenarchitektur bereitstellen.
Die theoretische Grundlage: Der DAG und der Zustand
Um den Unterschied zwischen Workflows und DLT zu verstehen, müssen wir uns mit der Graphentheorie und dem Zustandsmanagement befassen.
Jede data pipeline ist im Wesentlichen ein Directed Acyclic Graph (DAG). Daten bewegen sich von Knoten A (Bronze) zu Knoten B (Silver), aber niemals zurück.
1. Das imperative Modell (Databricks Workflows)
In einem imperativen Modell sind Sie der Graph-Bauer. Sie definieren die Kanten des Graphen explizit.
- Theorie: Sie definieren den Control Flow. Sie sagen dem System: "Führe Aufgabe A aus. Wenn erfolgreich, führe Aufgabe B aus." Dies gibt Ihnen maximale Kontrolle, erfordert jedoch eine sorgfältige, manuelle Abhängigkeitszuordnung.
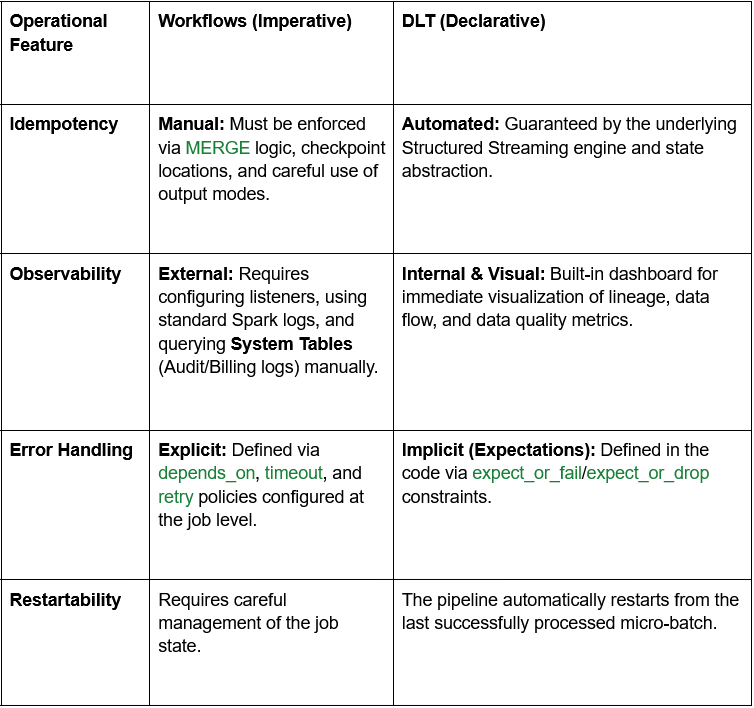
- Zustandsmanagement: Sie sind für den Zustand verantwortlich. Wenn der Job auf halbem Weg fehlschlägt, müssen Sie sicherstellen, dass das erneute Ausführen idempotent ist (garantiert das gleiche Ergebnis liefert). Dies erfordert oft die manuelle Konfiguration von Checkpoint-Standorten, das Handling von Dateisperren und die explizite Verwaltung von Transaktionsprotokollen.
2. Das deklarative Modell (Delta Live Tables)
In einem deklarativen Modell definieren Sie die Knoten; das System baut den Graphen.
- Theorie: Sie definieren den Data Flow. Sie sagen dem System: "Tabelle B wird als Transformation von Tabelle A definiert." Sie geben nicht an, wann oder wie die Zwischenschritte ausgeführt werden sollen.
- Topologische Sortierung: Die DLT-Engine analysiert alle Tabellendefinitionen, identifiziert Abhängigkeiten und führt eine "topologische Sortierung" durch, um die optimale Ausführungsreihenfolge zu bestimmen. Sie verwaltet automatisch parallele Ausführungspfade und Aufgabenabhängigkeiten.
- Zustandsabstraktion: Das System abstrahiert den Zustand. Es verwaltet automatisch die Checkpoints, die Schema-Evolution und die "genau-einmal"-Verarbeitungsgarantien von Spark Structured Streaming, wodurch Boilerplate-Code drastisch reduziert wird.
DLT im Detail: Das deklarative Paradigma und die Architekturplatzierung
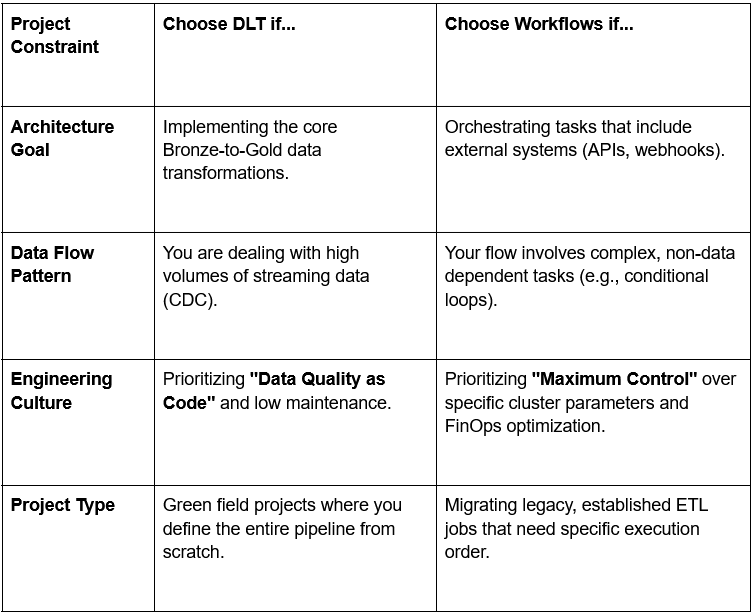
DLT glänzt bei der Implementierung der Medallion-Architektur (Bronze, Silver, Gold). Es ist darauf ausgelegt, die Transformationen zwischen diesen Qualitätsstufen zu definieren.
🥉 Bronze-Schicht: Vereinfachte Ingestion mit Auto Loader
DLT arbeitet nahtlos mit Auto Loader für eine zuverlässige, inkrementelle Ingestion aus Azure Data Lake Storage (ADLS) oder anderen Cloud-Speichern.
- Architektonischer Vorteil: Sie deklarieren einfach ein dlt.read_stream("cloudFiles", ...) und DLT übernimmt das Dateitracking und die genau-einmal-Verarbeitung, wodurch die Notwendigkeit für manuelle Konfigurationen von Dateibenachrichtigungen oder komplexen Streaming-Setups entfällt.
🥈 Silver-Schicht: Datenqualität als Code
Dies ist der wertvollste Beitrag von DLT. Es verlagert die Datenqualitätsprüfung von einem nachgelagerten Verarbeitungsschritt zu einem Inline-Validierungsschritt.
- Theorie der Erwartungen: Sie definieren Einschränkungen (z. B. Eindeutigkeit, Nicht-Null-Werte) mit Python- oder SQL-Dekoratoren. Dies erzwingt einen Datenvertrag auf der Silver-Schicht. Wenn Daten den Vertrag verletzen, kann DLT automatisch expect_or_drop (die fehlerhaften Daten isolieren) oder expect_or_fail (die Pipeline bei kritischen Fehlern stoppen).
- Schema-Evolution: DLT ist sehr meinungsstark in Bezug auf die Schema-Verwaltung und automatisiert häufig die Erkennung und Evolution von Schemas, ein häufiges Problem in Streaming-Pipelines.
FinOps und Cluster-Abstraktion
DLT verwendet standardmäßig Enhanced Autoscaling. Anstatt sich auf den traditionellen Spark-Autoscaler zu verlassen (der langsam reagieren kann), optimiert DLT die Clustergröße basierend auf der Flussrate und Latenz des Ausführungsgraphen der Pipeline.
- Kostenabstraktion: Während Sie die feingranulare Kontrolle über den Clustertyp für einzelne Knoten verlieren, ist das automatische Scaling von DLT oft effizienter für variable Workloads, was langfristig zu niedrigeren Betriebskosten führt, da ungenutzte Ressourcen schnell heruntergefahren werden.
Workflows im Detail: Der imperative Ansatz und Control Flow
Workflows sind die Grundlage für Plattform-Engineering und Control Flow. Sie bieten maximale Flexibilität außerhalb von Datentransformationen.
Interoperabilität und Control Flow
Workflows glänzen, wenn die Pipeline-Ausführung nicht rein datenbasiert ist:
- Vorverarbeitungsprüfungen: Ausführen eines Pre-Flight-Checks in Python (z. B. Validierung von Berechtigungen in Azure Key Vault oder Überprüfung der Dateiexistenz über eine Azure Function).
- Externe API-Aufrufe: Durchführen eines REST-API-Aufrufs (z. B. mit Postman-Mustern), um ein machine learning-Modell auszulösen, ein nachgelagertes System zu benachrichtigen oder Konfigurationen dynamisch abzurufen.
- Schleifen und Bedingungen: Workflows ermöglichen die Definition von bedingter Logik (z. B. Ausführen von Aufgabe C nur, wenn Aufgabe B fehlschlägt oder wenn ein Parameter auf True gesetzt ist).
Maximale Anpassung und FinOps
Für Umgebungen mit strengen Budgetvorgaben bieten Workflows die notwendigen Hebel für FinOps (Financial Operations):
- Optimierung auf Knotenebene: Sie können für jede Aufgabe individuelle, optimierte Clusterkonfigurationen festlegen. Eine leichte SQL-Abfrage kann auf einem kleinen serverlosen SQL-Warehouse ausgeführt werden, während ein komplexer PySpark-ETL-Schritt auf einem hochoptimierten Allzweck-Cluster läuft.
- Spot-Instance-Strategie: Sie können die Nutzung von Spot-Instanzen (preemptible VMs) für nicht-kritische, fehlertolerante Aufgaben präzise konfigurieren, um maximale Kosteneinsparungen zu erzielen, etwas, das DLT abstrahiert.
Die operative Sicht: Überwachung und Zuverlässigkeit
Unabhängig von der Wahl ist Zuverlässigkeit entscheidend. Hier sind die Unterschiede im Betrieb:
Die hybride Lösung: Das Workflow-Container-Muster
In fast allen anspruchsvollen Unternehmensumgebungen ist die Lösung nicht entweder-oder, sondern eine strategische Kombination: das Workflow-Container-Muster.
- Workflows fungieren als Controller (C): Sie verwalten die Planung, die Parameter und die Fehlermeldungen. Sie stellen sicher, dass der gesamte Lebenszyklus des Datenprodukts korrekt abläuft.
- DLT fungiert als Engine (E): Es ist innerhalb der Workflow-Aufgabenstruktur verschachtelt. Es führt die Kern-Datentransformation aus, garantiert Qualität, hohe Zuverlässigkeit und bewältigt die Komplexitäten des Stream-Zustands.
Dieses Muster nutzt die Automatisierung der DLT-Engine für die schwierigen Datenverarbeitungsteile, während die notwendige imperative Kontrolle beibehalten wird, um mit dem breiteren Azure-Ökosystem zu interagieren (z. B. mit einer Azure DevOps-Pipeline, um die DLT-Definition über DABs bereitzustellen und dann die resultierende DLT-Pipeline mit einer Workflow-Aufgabe zu planen).
Entscheidungsrahmen: Wann sollte man was wählen?